Les données non structurées changent la façon dont nous gérons, stockons et analysons les données applicatives et de production. Mais que sont les données non structurées, pourquoi sont-elles à la hausse et quels défis nous lancent-elles ?

LES DONNÉES NON STRUCTURÉES REPRÉSENTENT 80% DE TOUTES LES DONNÉES DES ENTREPRISES. AVEC UNE CROISSANCE ANNUELLE AU DELÀ DE 60%
Données structurées ou non structurées, quelles différences ?
DONNÉES STRUCTURÉES |
DONNÉES NON STRUCTURÉES |
|
|---|---|---|
|
Les données structurées sont généralement créées et stockées dans des bases de données relationnelles. Nous utilisons des champs précisément étiquetés pour les données que nous voulons stocker et utiliser. Un champ peut être un nom, un numéro, une date, une devise ou un prix par exemple.
|
Les données non structurées sont essentiellement tous les autres types de données, y compris:
La grande majorité des nouvelles données n'est pas structurée. Ces données sont beaucoup plus compliquées à rechercher, et à analyser. Il est donc plus difficile d'en extraire de l'intelligence. |
Quels sont les défis actuels des données non structurées ?
Les données non structurées et leur taux de croissance très important (1) concernent pratiquement toutes les entreprises, et pas seulement celles qui historiquement génèrent des quantités massives de données (instituts de recherche, sociétés audiovisuelles et pharmaceutiques, industries, etc.).
 Big Data, Hadoop, et l'Object Storage révolutionnent le stockage, la protection et l'exploitation des données.
Big Data, Hadoop, et l'Object Storage révolutionnent le stockage, la protection et l'exploitation des données.Aucune entreprise aujourd'hui ne peut échapper aux défis suivants:
- Infrastructure fantôme (Shadow IT): une infrastructure utilisée pour stocker et traiter les données non commerciales
- Copies multiples des données (Data sprawl): la multiplication des données par le partage de masse, la sauvegarde et l'archivage. Combien de copies de telle ou telle présentation Powerpoint circulent au sein de votre équipe et autour de votre organisation?
Par le passé, les données non structurées étaient plus statiques; rangées sur des disques et des bandes, et difficiles à exploiter et à analyser. Tout ceci change avec l'avènement du Big Data et des avancées technologiques telles que Hadoop (informatique distribuée) et le stockage objet de type S3 qui facilite le traitement et l'analyse des données non structurées.
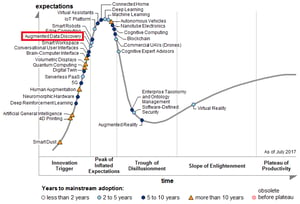 Augmented Data Discovery se positionne sur la pente de l'Innovation - Gartner Hype Cycle (2017).
Augmented Data Discovery se positionne sur la pente de l'Innovation - Gartner Hype Cycle (2017).Les analystes - y compris Gartner (2) - soulignent la nécessité d'utiliser l'intelligence artificielle (IA) et l'apprentissage automatique (Machine Learning) pour exploiter la richesse des informations stockées dans les données non structurées. Au cours de la prochaine décennie, les entreprises qui parviendront à extraire l'intelligence des données jadis statiques, y gagneront un réel avantage concurrentiel.
La croissance des volumes de données pose la question suivante: comment nous assurer que ces données restent accessible et stockées sur le long terme ? Et ce, sans provoquer d'augmentation exponentielle des coûts ?
STOCKAGE ET PROTECTION DES DONNÉES NON STRUCTURÉES
Bien sûr, le stockage de données ne consiste pas seulement à garder une copie unique. Les données non structurées sur un NAS ou sur d'autres plates-formes de stockage sont souvent répliquées, migrées, sauvegardées et archivées. Cela signifie qu'un To de données source se transforme rapidement en trois ou quatre To!
Atempo a les compétences pour déplacer et protéger des milliards de fichiers pouvant atteindre des pétaoctets de données non structurées. Toujours avec la possibilité de localiser une donnée et de la restaurer très rapidement avec les droits intactes.
Avec des solutions puissantes et économiques qui fonctionnent sur toutes les plateformes de stockage, les solutions de stockage intelligentes d'Atempo sont complètes et prêtes à l'emploi!
Pour plus de détails sur la protection et la gestion des données massives non structurées: Atempo.com
Références :

Laissez un commentaire